第六章:数据库故障处理
点击数:1754发布日期:2020-04-19 14:43:08 来源:oracle实战与提高
第六章:数据库故障处理
5.1故障处理概述
故障处理的工作要看运气。如果碰见很浅显的问题,那么三下五除二就药到病除了,几分钟的事儿。如果碰见那几样难办的问题,那谁碰上谁倒霉,刀架脖子上好几天也不敢说完全恢复。一般来说,数据库坏块,数据库死活起不来,数据丢失又没有备份算最惨的情况,碰上这三种情况,那考验我们的时候就到了,很可能要影响生产,造成损失,此类为高级别严重的事件。故障的原因五花八门,情况各异,本书中不可能将其完全涉及到,只能总结一些常见的故障,按故障的性质和根源进行分门别类,基本上我们碰见的问题,都在这些类别里。服务工作做久了,碰见的问题虽然很多,但大都是老一套,同样的问题在这个客户存在,那个客户也同样有。我们的目的不是处理故障显身手,而是避免故障的发生,让故障少发生甚至不发生,即使发生了故障也能有应急方案快速正确的解决,不影响生产,不给公司带来损失,这才是一个好的管理员。
5.2最常见的一些故障:
1、文件系统空间满了。可能被归档日志,trace文件,log文件,数据文件等撑满了。
2、表空间满了。长期增长,自动扩展到了32GB极限,数据库无人看守维护。
3、碰见bug了。使用的版本太低,碰见bug在所难免,最好升级。
4、达到参数设置的限额了。数据库参数,操作系统参数有最大值,超过就出问题。
5、SQL运行不出来。可能是统计信息错了或索引问题,也有的需要SQL调优。
6、统计信息错了。统计信息影响执行计划,要始终使用正确的统计信息。
7、误操作。误删除了表,误删除了文件,工具的原因,开的窗口太多了,混了。
8、硬件坏了,数据丢了。存储掉电重启后库起不来,主机坏,磁盘坏,网络坏等。
9、安装时该调整的某些项目没有调整到位,为日后运行埋下的隐患。
10、数据库锁,闩,死锁。
11、CPU利用率过高,看看是谁占的。
12、RAC交叉访问太多,需要分开应用,避免交叉访问。
13、参数设置错误,内存不够用,使用了错误的spfile。
5.3案例1:
|
故障描述 |
内容 |
解决结果 |
潜在影响及后续计划 |
|
存储损坏了五块磁盘,导致Oracle数据库已丢失。 需要对数据库进行恢复。数据库已经使用nbu进行备份,最后的备份集是9月18日,归档日志也只到9月18日,所以只能恢复到9月18日的数据。 |
控制文件丢失,redo日志丢失,数据文件丢失。 使用RMAN进行数据恢复。 |
数据库已恢复至9月18日。 |
注意巡检时,验证数据库备份是否已经成功。更换更可靠的存储设备。 |
5.3.1 数据库恢复
数据恢复过程参照:
先把数据库启动到nomount状态。恢复控制文件。
$rman target /
RMAN> restore controlfile to '/u01/oradata/yingshudb/control01.ctl' from '/orabak/yingshudbfull_YINGSHUD_20151026_7';
Starting restore at 2015-10-26 14:23:41
using channel ORA_DISK_1
channel ORA_DISK_1: restoring control file
channel ORA_DISK_1: restore complete, elapsed time: 00:00:01
Finished restore at 2015-10-26 14:23:42
恢复第二个控制文件:
RMAN> restore controlfile to '/u01/oradata/yingshudb/control02.ctl' from '/orabak/yingshudbfull_YINGSHUD_20151026_7';
有了控制文件,我们就可以把数据库启动到mount状态,恢复数据库了。
SQL> alter database mount;
Database altered.
恢复数据库:
RMAN> restore database;
Starting restore at 2015-10-26 14:30:49
released channel: ORA_DISK_1
allocated channel: ORA_DISK_1
channel ORA_DISK_1: SID=10 device type=DISK
channel ORA_DISK_1: starting datafile backup set restore
channel ORA_DISK_1: specifying datafile(s) to restore from backup set
channel ORA_DISK_1: restoring datafile 00001 to /u01/oradata/yingshudb/system01.dbf
... ...
Finished restore at 2015-10-26 14:34:05
还原数据库:
RMAN> recover database;
Starting recover at 2015-10-26 14:37:30
using channel ORA_DISK_1
starting media recovery
archived log for thread 1 with sequence 26 is already on disk as file
... ...
media recovery complete, elapsed time: 00:00:01
Finished recover at 2015-10-26 14:37:32
在SQLPLUS下,open数据库。
SQL> alter database open resetlogs;
Database altered.
5.4案例2:
核心数据库, 分别在10月9日和10月12日的16:50多分至17:05分左右分别出现连接数不够用和大量的” latch: library cache”, “cursor: pin S wait on X”等待事件。下面开始逐步对该等待事件产生原因进行分析。首先,获取该时间段内的AWR, ADDM报告进行分析:
AWR报告:
Top 5 Timed Events (10月9日)
|
Event |
Waits |
Time(s) |
Avg Wait(ms) |
% Total Call Time |
Wait Class |
|
latch: library cache |
1,542,461 |
384,954 |
250 |
57.9 |
Concurrency |
|
cursor: pin S wait on X |
19,302,183 |
188,954 |
10 |
28.4 |
Concurrency |
|
CPU time |
|
28,025 |
|
4.2 |
|
|
latch: undo global data |
249,410 |
25,958 |
104 |
3.9 |
Other |
|
latch free |
133,284 |
25,470 |
191 |
3.8 |
Other |
ADDM 报告:
10月9日 (16:00 -17:00):
FINDING 1: 45% impact (165019 seconds)
--------------------------------------
Soft parsing of SQL statements was consuming significant database time.
RECOMMENDATION 1: Application Analysis, 45% benefit (165019 seconds)
ACTION: Investigate application logic to keep open the frequently used
cursors. Note that cursors are closed by both cursor close calls and
session disconnects.
RECOMMENDATION 2: DB Configuration, 45% benefit (165019 seconds)
ACTION: Consider increasing the maximum number of open cursors a session
can have by increasing the value of parameter "open_cursors".
ACTION: Consider increasing the session cursor cache size by increasing
the value of parameter "session_cached_cursors".
--------------------------------------
Hard parsing SQL statements that encountered parse errors was consuming
significant database time.
RECOMMENDATION 1: Application Analysis, 31% benefit (114543 seconds)
ACTION: Investigate application logic to eliminate parse errors.
10月12日 (16:00 – 17:00):
Soft parsing of SQL statements was consuming significant database time.
RECOMMENDATION 1: Application Analysis, 44% benefit (294095 seconds)
ACTION: Investigate application logic to keep open the frequently used
cursors. Note that cursors are closed by both cursor close calls and
session disconnects.
RECOMMENDATION 2: DB Configuration, 44% benefit (294095 seconds)
ACTION: Consider increasing the maximum number of open cursors a session
can have by increasing the value of parameter "open_cursors".
ACTION: Consider increasing the session cursor cache size by increasing
the value of parameter "session_cached_cursors".
根据ADDM的建议,shared pool 解析压力偏大。硬解析量很多,建议把参数session_cached_cursors 由20增大到500。尽量减轻shared pool 的解析压力。
hard parse。 这里面提到的SQL语句均没有使用绑定变量,导致SQL语句版本增大,shared pool压力骤然增大。
建议open_cursors增大到3000。尽量减小出现open_cursors不足的错误,但根本还需要应用程序保障游标使用后及时关闭。
通过对比,发现主要还是在异常时段,会话开启的游标数太多(相对于稳定时段)。连接会话的游标开启增大。
10月12日 16:00 – 17:00 硬解析:(异常)
|
Statistic Name |
Time (s) |
% of DB Time |
|
parse time elapsed |
540,361.71 |
81.22 |
|
hard parse elapsed time |
246,266.63 |
37.02 |
|
failed parse elapsed time |
214,700.57 |
32.27 |
|
sql execute elapsed time |
77,603.29 |
11.66 |
建议:
(1): 建议所有应用程序使用绑定变量,避免出现SQL Version Count过高而导致shared pool压力太大的负担。相关SQL由下面SQL查出。
--查需绑定变量的SQL
col sql for 45
select substr(sql_text,1,40) "sql",
count(*) ,
sum(executions) "totexecs"
from v$sqlarea
where executions < 5
group by substr(sql_text,1,40)
having count(*) > 30
order by 2;
(2):10月9日和10月12日)出现两次ORA-00020: maximum number of processes (1600) exceeded报错,建议客户把process 适当增大至3000。
(3):建议客户把open_cursors增大到3000。把session_cached_cursors设置为500。
(4): 对于ORA-3136错误,可以按如下方式来进行解决:
1: 在listener.ora文件中添加如下语句:
inbound_connect_timeout_
2: 编辑sqlnet.ora文件追加如下语句:
sqlnet.inbound_connect_timeout=0
3: reload listener使其生效。
$ lsnrctl
reload
5.5经典案例3:
樱澍医院yszxyy系统数据库宕机,无法启动,经进一步查询得知是由于存储掉电,主机掉电,操作系统忽然关机所致。数据库在关闭时,alert没有来的及报任何错。
结论:
因操作系统忽然关机。相当于数据库在不一致的情况下abort。Buffer中的数据来不及写到数据文件中去。导致redo,control file,datafile的SCN号不同步。在启动的时候启不来,报ORA-600错误。
数据库没有备份。即没有RMAN全备,也没有近期的exp导出备份。
local_listener参数没有设置,连接不稳定,时断时续。
解决此问题的方法:
1、加隐含参数在不一致的情况下强制启动数据库。
2、重建undo表空间,将旧的undo表空间删除。
3、将数据导出。
4、重建新数据库。
5、将数据导入新数据库,旧库作废。
在本次故障处理中发现了一些问题,具体描述和建议会在下面的报告中详细阐述。
以下是一些主要问题和建议的总结。
|
No. |
主要问题 |
说明及参考 |
建议解决时间 |
|
1 |
定期删除alert.log及trace文件。 |
Alter日志过大,vi无法打开。本库的alter日志有600MB。 |
近期解决 |
|
2 |
定期删除listener.log。 |
Listener.log有2GB大。 |
近期解决 |
|
3 |
硬件已过保,建议新置硬件。 |
硬件已经运行七年以上,建议更新换代。 |
近期解决 |
|
4 |
注意磁盘空间利用率。 |
使用df -h |
近期解决 |
|
5 |
定期进行RMAN全备。 |
便于恢复。 |
近期解决 |
|
6 |
建议实现数据库的高可用。如DataGuard。 |
建议建立灾备系统 |
近期解决 |
|
|
|
|
|
|
|
|
|
|
我们在本次检查过程中,已就大多数问题及建议与樱澍医院的DBA进行了交流,并详细告之了具体的实施方法。非常感谢樱澍医院蔡恒恒在此次故障处理过程中给予我们的大力支持和配合。
sqlplus /nolog
conn /as sysdba
show parameter dump
警告日志没报错:
Thread 1 advanced to log sequence 1331 (LGWR switch)
Current log# 2 seq# 1331 mem# 0: +ORACLEASMDS3400/yszxyy/onlinelog/group_2.258.702315483
Current log# 2 seq# 1331 mem# 1: +ARCHDG/yszxyy/onlinelog/group_2.258.702315485
Mon Aug 2 07:48:52 2015
Starting ORACLE instance (normal)
LICENSE_MAX_SESSION = 0
2、强制启动数据库
SQL> conn /as sysdba
Connected to an idle instance.
SQL> startup nomount pfile = '/tempfs/pfile.ora';
ORACLE instance started.
Total System Global Area 2516582400 bytes
Fixed Size 2086032 bytes
Variable Size 905972592 bytes
Database Buffers 1593835520 bytes
Redo Buffers 14688256 bytes
SQL> alter database mount;
Database altered.
SQL> recover database until cancel;
ORA-00279: change 240795288 generated at 08/03/2015 00:16:24 needed for thread 1
ORA-00289: suggestion : +ARCHDG
ORA-00280: change 240795288 for thread 1 is in sequence #3
Specify log: {
cancel
ORA-01547: warning: RECOVER succeeded but OPEN RESETLOGS would get error below
ORA-01194: file 1 needs more recovery to be consistent
ORA-01110: data file 1: '+ORACLEASMDS3400/yszxyy/datafile/system.260.702315491'
ORA-01112: media recovery not started
startupmountpfile= '/tempfs/pfile.ora';
ALTER SESSION SET EVENTS '10015 TRACE NAME ADJUST_SCN LEVEL 3';
alter database open;
Database altered.
3、建立新的undo表空间
create undo tablespace undotbs3 datafile '+ORACLEASMDS3400/yszxyy/datafile/undotbs3' size 1000m;
alter system set undo_tablespace='UNDOTBS3’scope = spfile;
shutdown abort;
startup up;
drop tablespace undotbs1;
4、将数据库导出
exp ‘sys/oracle as sysdba’ buffer=20971520 full=y grants=y file=/tempfs/fulldb.dmp log=/tempfs/impfull_100803.log
5、新建数据库,使用dbca建库。
dbca
6、将数据库整库导入
imp sys/oracle buffer=20971520 full=y grants=y ignore=y file=/tempfs/fulldb.dmp log=/tempfs/impfull_100803.log
7、RMAN备份:省略。参见备份章节,制定合适的备份策略。
8、设置参数local_listener。解决连接问题。
主机12
alter system set local_listener='(address = (protocol = tcp)(host = 192.168.0.10) (port = 1521))' scope=both sid='YSZXYY1';
alter system set local_listener='(address = (protocol = tcp)(host = 192.168.0.11) (port = 1521))' scope=both sid='YSZXYY2';
5.6案例4:
总结
樱澍ysiis系统/home/oracle/出现异常的三种文件,heapdump,javacore,snap0001,经进一步诊断确认是由于数据库oem bug所致。经过和客户商议,暂时关闭oem功能,观察以后的状况。若不再现在此类问题,可以永久禁用oem。直至升级到11.2.0.4再启用。问题解决。
结论:
Oracle 11 g,11.1.7不是11g最稳定的版本,有bug比较难免。也可以考虑升级,升级前做好测试工作。
解决此问题的方法:
1、 停止oem web服务。
2、 停止oem服务。
emctl stop dbconsole
emctl stop agent
5.7案例5:
应客户要求,于2015-6-29上午11点到达现场,对ora-29740错误进行分析。
|
问题描述 |
内容 |
处理结果 |
潜在影响/后续措施 |
|
Trace dumping is performing id=[cdmp_20150629192723] Mon Jun 29 19:31:43 2015 Errors in file /app/oracle/admin/ysccsm/bdump/ysccsm2_lmon_19538.trc: ORA-29740: evicted by member 1, group incarnation 52 |
Mon Jun 29 19:31:43 2015,RAC数据库ysccsm2实例,发生宕机。 |
事故原因: 私有网络通信故障。 RAC负载过重。 是否已经考虑RAC节点分开应用,避免交叉访问。 |
建议布署OSW。监控网络priv网卡通信情况。
监控Oracle数据库压力情况。 |
1. alert_ysccsm2.log
Mon Jun 29 19:27:27 2015
Trace dumping is performing id=[cdmp_20150628192723]
Mon Jun 29 19:31:43 2015
Errors in file /app/oracle/admin/ysccsm/bdump/ysccsm2_lmon_19538.trc:
ORA-29740: evicted by member 1, group incarnation 52
Mon Jun 29 19:31:43 2015
LMON: terminating instance due to error 29740
Mon Jun 29 19:31:43 2015
Errors in file /app/oracle/admin/ysccsm/bdump/ysccsm2_lms0_19542.trc:
ORA-29740: evicted by member , group incarnation
Mon Jun 29 19:31:43 2015
Errors in file /app/oracle/admin/ysccsm/bdump/ysccsm2_lms1_19544.trc:
... ...
Tue Jun 29 09:34:17 2015
Starting ORACLE instance (normal)
2. ysccsm2_lmon_19538.trc
*** 2015-06-29 19:19:57.115
kjxgrcomerr: Communications reconfig: instance 0 (51,51)
Submitting asynchronized dump request [2]
kjxgrrcfgchk: Initiating reconfig, reason 3
*** 2015-06-29 19:20:02.185
kjxgmrcfg: Reconfiguration started, reason 3
kjxgmcs: Setting state to 51 0.
*** 2015-06-29 19:20:02.190
Name Service frozen
kjxgmcs: Setting state to 51 1.
*** 2015-06-29 19:20:02.484
Obtained RR update lock for sequence 51, RR seq 51
3. alert_ysccsm1.log
Mon Jun 29 19:19:57 2015
Trace dumping is performing id=[00628191957]
Mon Jun 29 19:21:43 2015
Waiting for clusterware split-brain resolution
Mon Jun 29 19:26:06 2015
Errors in file /app/oracle/admin/ysccsm/bdump/ysccsm1_diag_7589.trc:
ORA-00600: internal error code, arguments: [17182], [0x1037DF9C8], [], [], [], [], [], []
Mon Jun 29 19:27:15 2015
Restarting dead background process DIAG
DIAG started with pid=3
4. alert_ysccsm1.log
******************************************************
HEAP DUMP heap name="pga heap" desc=1036a6030
extent sz=0x2190 alt=168 het=32767 rec=0 flg=3 opc=2
parent=0 owner=0 nex=0 xsz=0x4068
EXTENT 0 addr=107d5bc98
Chunk 107d5bca8 sz= 16472 freeable "KST Heap " ds=1036ab250
… …
6C271444:00000008 3 0 10401 28 KSXPMAP: client 1 base 0x3800c0000 size 0x8d6f40000
KSTDUMP: End of in-memory trace dump
DIAG detachs from CM
error 600 detected in background process
OPIRIP: Uncaught error 447. Error stack:
下一篇:第七章:数据库调优艺术
上一篇:第五章:数据库的备份和恢复
图文推荐
 序言
序言
2020-04-19 查看:3097
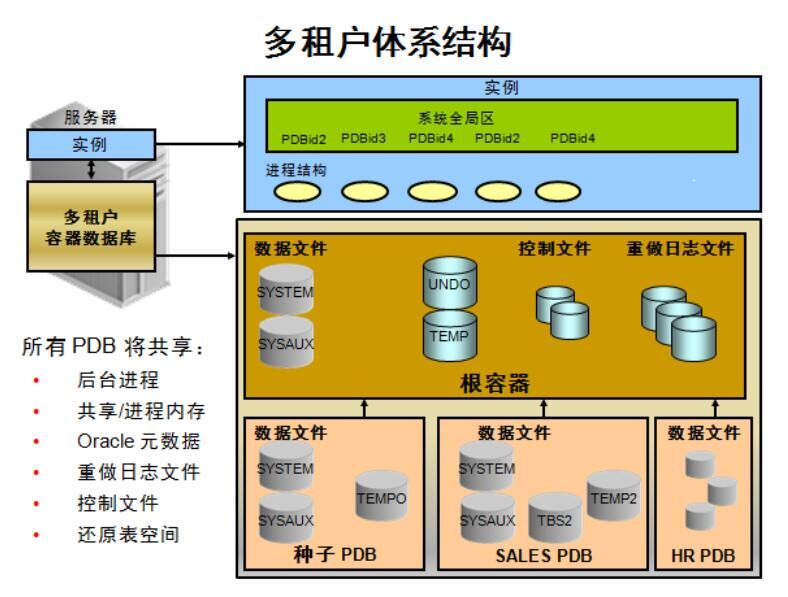 第十五章:Oracle 12c介绍
第十五章:Oracle 12c介绍
2020-04-19 查看:3048
 第十四章:常用Oracle工具
第十四章:常用Oracle工具
2020-04-19 查看:2729
 第十三章:Oracle Golde...
第十三章:Oracle Golde...
2020-04-19 查看:2988
 第十二章:DataGuard
第十二章:DataGuard
2020-04-19 查看:2543
